DIPROニュース
AI×CAD / CAE時代のデータマネジメント
~ 蓄積データ価値を最大化する4ステージ ~
今回は、これまでのDIPROニュースの記事(2023年2月号、2024年2月号)を踏まえて、製品開発の検討高度化とフロントローディングのために、蓄積データの価値を最大化するデータマネジメントにフォーカスし、以下について説明します。
- 蓄積データとデータマネジメントについて
- 管理し易いデータ=構造化データについて
- 構造化された開発データと開発検討の高度化&フロントローディング
- 課題 / 取り組みとDIPROのご支援
【関連記事】
“モノづくり”へのデータサイエンス活用の取り組み ~ 設計開発知見の蓄積と活用に向けて ~ [2023年2月号]
“モノづくり”へのデータサイエンス活用の取り組み ~ 開発の上流工程における検討高度化に向けて ~ [2024年2月号]
蓄積データとデータマネジメントについて
データ活用が大事であるとか、データには価値があるといった話をよく耳にします。ここではその理由を少し考えたいと思います。
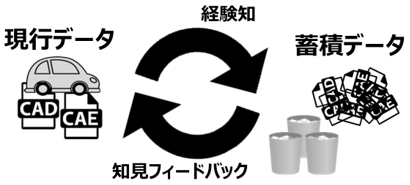
私達は日々生産活動することで、製品やサービスを作り出しています。企画検討から生産まで大量の検討データが生まれます。その過程で採用されなかった多くの検討データが捨てられているか、利用されずにただ保存されていると思います。これら大量のデータに対して手間を加えて精製 / 整理し、検索し易いように管理されたデータを現行の検討データと合わせて新製品開発で使うことは、現在進行形の検討データに経験知としての蓄積データによるフィードバックを加えることになり、開発検討において、過去データ(蓄積データ)が現在作成中のデータの価値を引き出します。
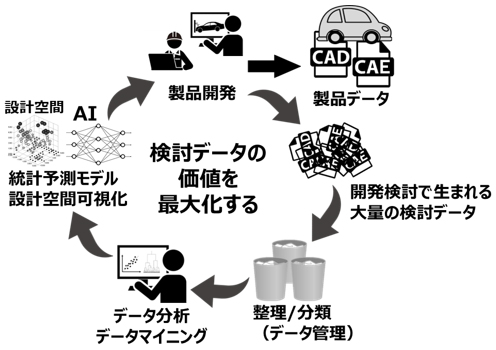
管理し易いデータ=構造化データについて
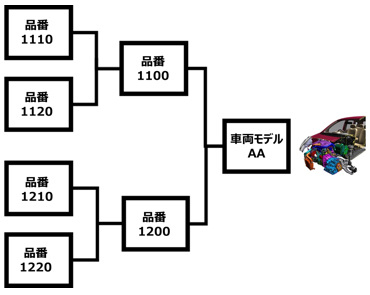
検索し易いように管理できるデータとそうでないデータの違いは何でしょうか?管理し易いデータは一般に構造化データと呼ばれます。これは、「行」と「列」を持つテーブル形式で記録でき、複数のテーブルデータを関連付けて整理出来るタイプのデータのことであり、データベース管理と相性の良いデータのことです。設計開発データの例であれば、部品表や部品ID、設計変更履歴、実験の数値データなどです。
一方で、管理が難しいデータは非構造化データと呼ばれ、テキスト、画像、音声、動画などのデータです。設計開発データの例であれば、CADやCAEのデータ、設計レビュー議事録などのドキュメント、実験の画像や動画などです。
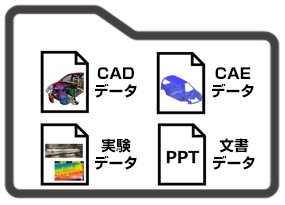
設計開発データにおいてCADは非構造化データに分類されますが、設計諸元値はテーブル形式で整理が可能ですので、構造化データに分類できます。このように設計開発のデータは構造化データと非構造化データが混在しており、データドリブンな製品開発を進める上で検討の高速化と高度化のボトルネックになりつつあります。
構造化データと開発検討の高度化&フロントローディング
前章でも述べましたが、設計諸元値はテーブル形式で整理が可能ですので、構造化データに分類できます。この設計諸元値は開発検討の高度化と開発フロントローディングを進める上で重要になってきます。その理由を簡単に以下に述べます。
現代の製品は、数多くのユニット・部品で構成され、その設計担当も分かれています。各ユニット・部品の性能が予測検討により作り込まれ具体的な形状になり、製品全体の構成情報が決まってきます。
自動車を例に出すと、衝突安全や乗り心地、音振、空調など、製品全体や複数のユニット・部品の設計情報により性能が決まるものがあります。これらは、各ユニット・部品の性能が作り込まれ具体的な形状になってようやく、3DCAEなどで詳細に性能評価されるものです。しかし、このタイミングにおける性能評価でNGが出た場合、各ユニット・部品の設計が作り込まれているため、設計変更の余裕シロが少なく、このタイミングから性能評価をOKにすることは容易ではありません。
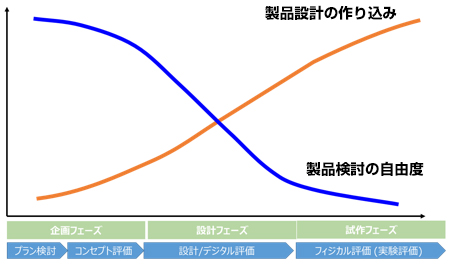
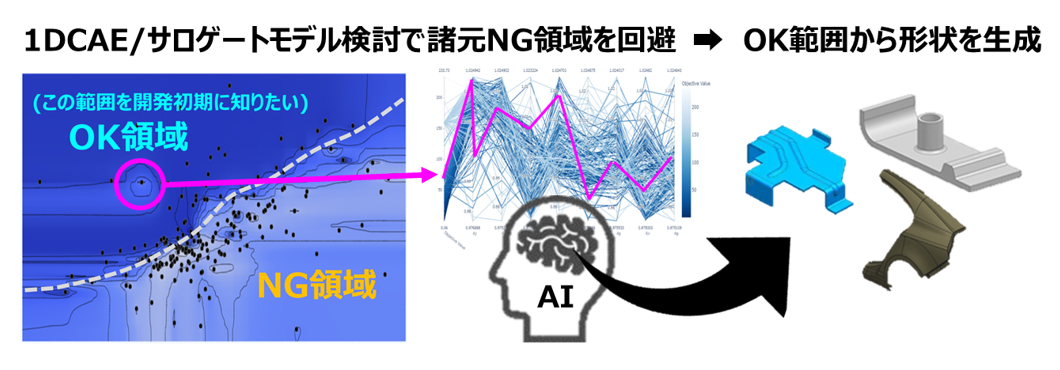
製品開発エンジニアの苦労を減らすための仕組みとして、3DCAEで評価する前から共有された性能指標と設計諸元値を使うことで複数ユニット・部品にまたがる性能を評価し、具体的な設計情報が決まる前に、致命的なNGを出さないようにする方法が考えられます。その手段として、過去のDIPROニュースで取り上げている設計諸元値を使って性能の予測を行う1DCAEやサロゲートモデルがあります。
例えば、開発初期に設計諸元値のOK / NG領域をサロゲートモデルで検討することで、開発検討の高度化と開発フロントローディングが期待できます。また、最近では生成AIを利用したCAD生成も技術的に可能になってきており、設計諸元値のOK / NG領域をサロゲートモデルで検討すると同時に、候補形状を素早く確認すると言ったユースケースが出てくると考えられます。
課題取り組みとDIPROのご支援
検討データを開発フロントローディングに役立てるためには、諸元値管理を含めたデータマネジメントが重要であることを説明しました。これらを構築するには、以下①~④のステージの課題があり、これらの課題解決の難しさは、製品性能の予測に直結するCADやCAEデータなど開発データの多くが、非構造化データであり設計内容に紐づいた検索が容易でないことにあります。DIPROはその課題への取り組みをご支援いたします。
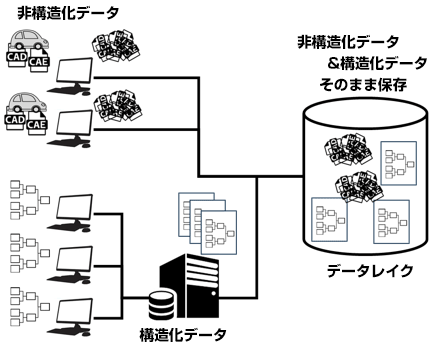
ステージ①:構造化データと非構造化データを格納するシステム(仕組み)の用意
非構造化データも構造化データもデータですので、その格納先がそもそも必要です。CADやCAEなどの非構造化データもリンクとして利用したいユーザーが参照できる形式で格納出来る仕組み(システム)を準備することが第一歩になります。
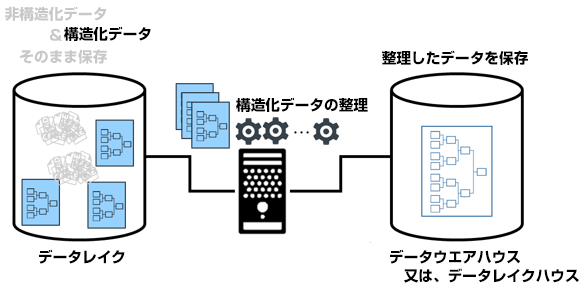
ステージ②:構造化データの整理と管理
構造化データに対して関係するデータの分析を行った後、関係するデータを関連付けて整理できるデータベースとして管理し、検索システムと連携が行えるようにする必要があります。
ステージ③:性能予測に感度のある設計情報の諸元値化と構造化データの紐づけ
CADやCAEなどの非構造化データもリンクとして参照できる状態であるため、解析エンジニアや設計者、専任の分析者がデータサイエンスを活用したデータ分析により、性能予測に感度のある設計情報としての諸元値登録と既存の構造化データへの紐づけも合わせて行います。
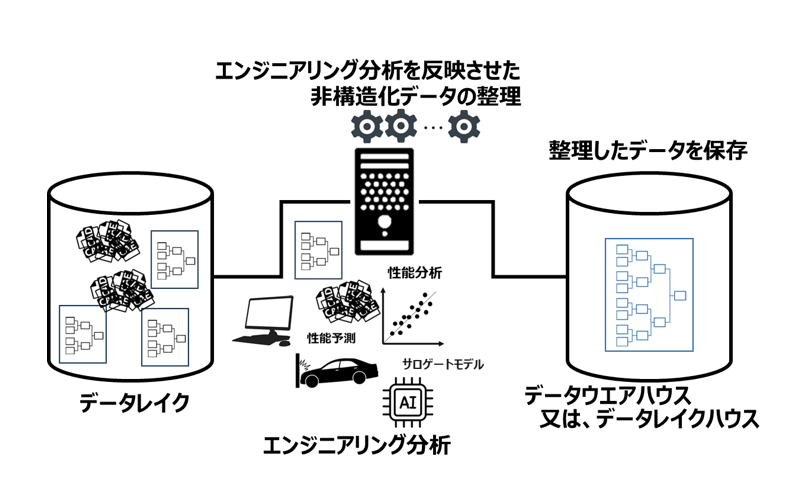
ステージ④:データ活用しながら非構造化データの構造化範囲を拡大
製品開発は途切れることなく行われるので、ステージ③までのデータを活用しながら新規データの追加と、対象データをドキュメントまで拡大させるなどデータの構造化範囲の拡大を続けることが大事です。
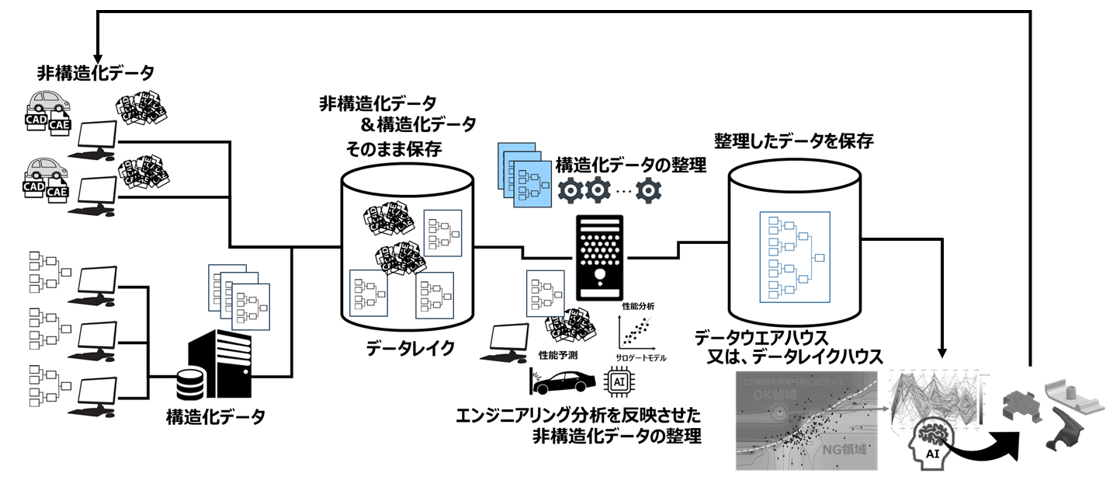
昨今では大規模言語モデル(LLM=Large Language Model)の急激な進化により、AIエージェントの業務利用への期待が高まっています。関連してAIエージェント自体が社内データを検索し、社内ツールと連携するためのMCP(Model Context Protocol)と呼ばれる仕組みが出てきています。そのため、上記①~④の取り組みにより資産である開発検討データをMCPに接続することで秘匿性の高い開発検討データもAIエージェントが活用できるようになるため、蓄積データの価値を最大化するためのデータマネジメントが、益々重要になってきています。
お問い合わせ先
PICK UP
-

ソーリンク様のVR活用 「顧客と共創する装置開発」 ~ 手戻りを減らし、対話を深め、信頼につなげる ~
-

Fujitsu デジタル生産準備VPSお客様事例 株式会社東光高岳 様
-
Teamcenter 製品アップデート 情報をより使いやすく! AI機能「Teamcenter Copilot」ご紹介
-

株式会社東野精機様 iCADフォルダ管理連携 システムの運用事例紹介
-

Fujitsu デジタル生産準備VPS お客様事例 創美クラフトポーランド株式会社 様
-
Teamcenter Assistant Preset(TCAP)ご紹介
-

VRを活用した生産準備業務のフロント ローディングへ向けて ~ 株式会社アドヴィックス様における Xphere活用事例 ~
-

3Dデータと点群データによる最先端VR営業 ~ 株式会社ヤマウラ様における VridgeR / Xphere活用事例 ~
-

COLMINA デジタル生産準備VPSお客様事例 株式会社SUBARU モノづくり本部 生産技術統括部 様
-

COLMINA デジタル生産準備VPSお客様事例 富士工業株式会社 ものづくり革新本部 技術部 技術2課 様
-

宇通バス様DIPROMEBIUSχの運用事例紹介
-

ポストコロナにおけるものづくり現場の デジタル化 ~ 株式会社ソーリンク様におけるXphere 活用事例 ~